[img][/img]
原创文章,转载请注明出处 nutch群:74985182 欢迎加入交流
nutch是在hadoop基础上做的,由于hadoop只在linux上运行,里面涉及到大量的操作linux程序,所以我们在部署的时候必须先安装cygwin环境
一、安装cygwin环境cygwin是windows下模拟linux环境的免费软件
下载安装程序:
http://www.cygwin.com/setup.exe
安装完成后运行setup.exe点击下一步如下图
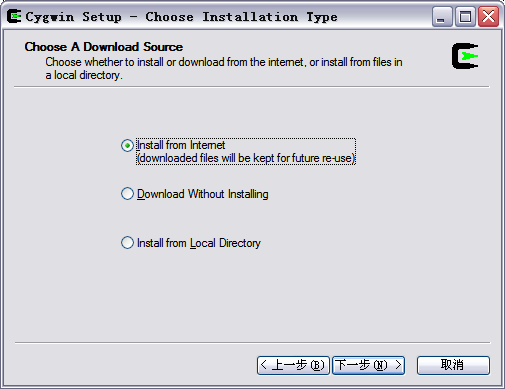
界面出现三种安装模式:
Install from Internet,这种模式直接从Internet安装,适合网速较快的情况;
Download Without Installing,这种模式只从网上下载Cygwin的组件包,但不安装;
Install from Local Directory,这种模式与上面第二种模式对应,当你的Cygwin组件包已经下载到本地,则可以使用此模式从本地安装Cygwin。
我选择直接下载(下载这东西超费劲)
下一步后出现一下界面需要选择安装目录
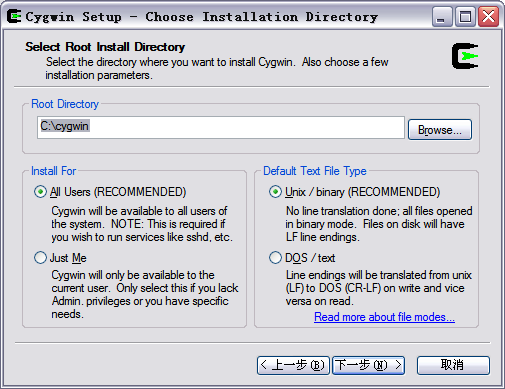
默认在C:\cygwin\,你也可以选择自己的安装目录,然后选择“下一步”
这一步我们可以选择安装过程中从网上下载的Cygwin组件包的保存位置,选择完以后,点击“下一步”
这一步选择连接的方式,选择你的连接方式,选默认的“diret Connection”然后选择“下一步”
这一步需要选择下载的服务地址,寻找Cygwin中国镜像的地址:http://www.cygwin.cn,如果找不到就add一下。我图方便选择了tw的地址,点击“下一步”
这一步选择需要安装的内容
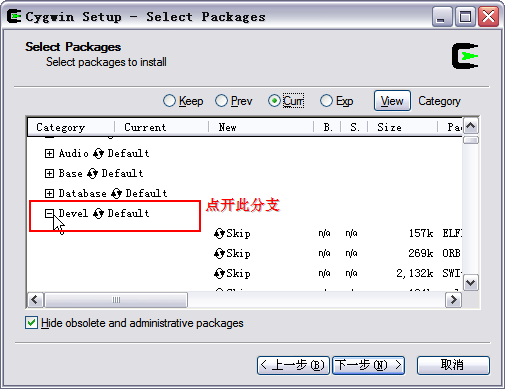
常用的有default列表(表示值安装默认的安装项)、Install(表示安装全部程序)、Reinstall(表示重新安装程序),如果带宽允许就安装Install,一步到位,这样至少会下载1.5G的东东哦。我选择的是default主要是带宽慢,不知道以后会不会少东西,少了再补吧。哈哈。点击“下一步”
然后就都选默认就OK了
然后把cygwin/bin加入环境变量的path中。
二、Eclipse中部署nutch
首先下载nutch,可以用svn或者到apache下载
nutch的主页是:http://lucene.apache.org/nutch/目前最新是1.3.下载tar.gz的文件。下载后解压到目录(我选择了D:/nutch).解压完成后打开eclipse
选择 file->新建->java project
选择 browse 按钮 选择工程解压到所在目录,在project name 写上project 名称。

点击下一步 选择libraries标签 然后选择Add Class Folder按钮 把conf文件夹加入
点击order and Export 标签 把conf置顶(top)
这步非常重要,我就是因为没有操作这步报了找不到plugin 的异常,看了官网才发现在测试文件 src/test中也有conf目录,而nutch会去找src/test/conf目录
然后选择finished完成!
然后会发现很多jar包没有,只需要选择build.xml 右键 -> run as ->ant build
便会下载所有的jar包。然后手动导入即可。
下面开始配置简单抓取
1. 在src目录下创建文件夹 urls
在urls文件夹下创建url.txt文件
在url.txt文件中加入需要抓取的链接
例如我下载的搜狐汽车我便加入
http://auto.sohu.com/
注意:必须以/结尾
2.配置nutch-site.xml
<configuration>
<property>
<name>http.agent.name</name>
<value>nutch-1.3</value>
<description>user-agent这里可以自己写,伪装成IE或者谷歌爬虫等</description>
</property>
<property>
<name>searcher.dir</name>
<value>F:\testdb\ser</value>
<description>索引目录.</description>
</property>
<property>
<name>http.agent.url</name>
<value>http://www.google.com/</value>
<description>爬虫网站</description>
</property>
<property>
<name>http.agent.email</name>
<value>google@gmail.com</value>
<description>可以联系到爬虫的mail</description>
</property>
</configuration>
3.配置nutch-default.xml
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
<description>Directories where nutch plugins are located. Each
element may be a relative or absolute path. If absolute, it is used
as is. If relative, it is searched for on the classpath.</description>
</property>
4.配置regex-urlfilter.txt
# accept anything else
+^http://([a-z0-9]*\.)*sohu.com/
这里主要是根据自己的条件来过滤不需要下载的链接
5.运行

如果需要solr就配置上 -solr http://localhost:8983/solr/
这个地址是solr服务的地址,需要先启动solr后才可配置,否则会报找不到solr服务的异常
否则可以忽略
配置完成后直接运行就可以了!
nutch1.3初步就配置完成了。
分享到:





相关推荐
eclipse配置nutch,eclipse配置nutch
nutch1.3在myclipse部署工程源码nutch1.3在myclipse部署工程源码nutch1.3在myclipse部署工程源码
配置好的Nutch1.3开发环境,解压后直接导入Eclipse Workspace即可,调试通过,默认爬163两层,解决Eclipse3.6+版本无基于源码创建工程选项问题
Nutch 1.3 学习笔记,讲的比较清楚的文档
Windows下使用Eclipse配置Nutch2图文详解
Eclipse 中编译 Nutch-1.0 运行源代码
apache-nutch-1.3 的源码包,需要的可以看下
Eclipse 编译 Nutch-0.9
nutch-1.3源码,java版本,其他请参看手册。
本文章修改了在eclipse中加入Nutch的详细过程!
1.1 环境准备 1.1.1 本期引言 1.1.2 环境介绍 1.1.3 JDK 安装配置 1.1.4 ANT 安装配置 1.1.5 IvyDE 安装配置 1.1.5 Tomcat 安装配置 ...1.2 Eclipse 开发 1.2.1 Solr 部署 1.2.2 Nutch 导入 1.2.3 Solr 与Nutch 结合
一个解析MP3,一个解析rtf文件
Nutch是一个由Java实现的,刚刚诞生开放源代码(open-source)的web搜索引擎。 尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步... Nutch目前最新的版本为version1.3。
nutch配置nutch-default.xml
nutch 在windows下环境搭配 已经如何在eclipse下配置,有配图,很详细
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫
一步一步详细解释了如何搭建nutch web开发环境,对nutch1.2有效,nutch1.3以上已经没有web这部分内容了
Nutch是一个由Java实现的,刚刚诞生开放源代码(open-source)的web搜索引擎。
Nutch在Tomcat下的部署.doc
Eclipse中编译Nutch-1.0。。。。。。。。。。。。